@capascualm muchas gracias por su aporte, a mi personalmente encantaría ver el código y conocer sus pesquisas. Yo aún estoy meciéndome en el insondable océano de la teoría, intentando entender el amor, la vida y el PER, pero mi corazoncito sabe que algún día debo dar el salto para conocer los fundamentales de las empresas y todo ahorro de energía para ese momento será poco.
4 Me gusta
Esto se está poniendo muy interesante ![]()
![]()
4 Me gusta
Hola amigos. @capascualm felicitarle por ese gran paso! Qué bueno! Me sumo a la palabras de @inyaki.sainz, @AlanTuring y @arturop. A mí también me encantaría poder echar un ojo al código. Aunque de formación soy informático hace tiempo que no programo pero es una disciplina que me encanta. Muy a favor de crear ese repositorio GitHub.
En paralelo, les cuento novedades. Por un lado en el máster de dirección financiera no me aceptan como TFM un estudio de técnicas cuantitativas para la inversión por fundamentales. Me dicen que no es una competencia core de un dpto. financiero. En fin. Va a parar eso a uno de Bilbao? Nada de eso, simplemente lo frena 
Junto con esto estoy a las puertas de cambios profesionales, con cierto vértigo también les reconozco, y poquito tiempo para las inversiones.
Me compré hace unas semanas What Works on Wall Street y es una maravilla con un montón de modelos y backtests históricos. Viendo que ustedes avanzan en la parte más técnica de desarrollo, si puedo sacar tiempo (y sobre todo consigo centrarme) estaré encantado de poder crear un documento con una batería de modelos que sirvan como base. Podría subirse a ese repositorio y sembrar la semilla del +D Quant Lab.
Un saludo a todos.
9 Me gusta
Muy interesante el screener.
Desde mi más humilde opinión, ¿y si añade algún factor que seleccione a las más baratas de ese grupo?
Creo que el punto de partida de Greenblatt de ROCE + PER (o EV/EBIT) es necesario para evitar compras a múltiplos altos ¿ha realizado el backtest en 2008?
Con esos dos puntos de partida hay formas de sacarle alpha con sentido común (añadiendo algo de sal o pimienta: momentum, pietroski, endeudamiento, current ratio, etc).
De hecho podría probar: alto roce, bajo EV/EBIT, alto FCF growth, fondo de maniobra positivo y 1 año para rotar (incluyendo small y mid cap, mercado USA).
Igual lo probó usted ya y no mejora el backtest.
Gracias por su aportación y aquí uno que quiere aprender quant.
3 Me gusta
Una pregunta general , cuando analizais la rentabilidad considerando un balance y una p&l , tenemos como sabeis muchas opciones roe, roa, roic y roce, cual es vuestra preferida?. . En los foros mucha gente menciona el ROIC en lugar del ROCE. Yo prefiero el ROCE, no sólo porque lo he visto más en mi actividad profesional sino porque el ROIC en teoría está ajustado por el tipo impositivo y el ROCE no. a favor el ROIC debo decir que tiene en cuenta sólo el dinero invertido en el negocio (se restaría la caja) y el ROCE por el contrario, tiene en cuenta todo el capital empleado. La filosofía del ROIC me gusta porque busca la rentabilidad del business pero el hecho de que se post tax hace que su comparativa con otras compañías internacionales no sea un" like to like" por los diferentes tipos impositivos. El Roce tiene un calculo sencillo y aunque nos muestra una rentabilidad menos afinada al core del business , es pre tax y al final facilita su comparación .Además en el ROCE incluimos todos los recursos que se invirtieron en la empresa y no solo algunos. Imaginad una conpañia q hace una ampliación de capital y se gasta solo un 80 por cien y el resto queda en caja, utilizando el roic no penalizo el capital ocioso en el cálculo de la,rentabilidad pero el ROCE si lo penaliza y creo q así debe ser…es una chorrada todo esto e igual tiene poco sentido pero me apetecía hacer esta reflexión con vosotros . Viva el ROCE!
8 Me gusta
Muchas gracias por las ideas. En cuanto saque el tiempo necesario me pondré con ello. A día de hoy me cuesta la vida hacer cada uno de los backtest (mi background es de ingeniero industrial y apenas aprendí algo de C++ en la carrera).
Lo que si que puedo decir es que he probado con momentum de los 6 últimos meses (además de FCF growth y ROIC), excluyendo el último mes (cómo lei que hacia Asness) y aunque si que es cierto que da muy buenos resultados en épocas de bonanza, aumenta mucho la volatilidad y hace que en un 2008 te hundas y bueno ya sabéis como es esto de para recuperar un -10% de caída, hay que hacer un +11% (and so on). Tengo por ahi el resultado pero en rentabilidad, no conseguía superar al que he subido y eso que llevamos mas de 10 años con las bolsas en verde
3 Me gusta
Es una pena por que tenía ganas de ver en qué acababa ese TFM, hubiera sido matar 2 pájaros de un tiro. ![]()
2 Me gusta
Finalmente me he tomado el lujo de crear el repositorio Git por mi cuenta y subirlo directamente ahí. En principio no me ha sido complicado generar el repositorio y hacerlo público, ahora será otro tema cuando empecemos a hacer revisiones, asignar colaboradores, nuevas versiones… Pero creo que como inicio para que echéis una ojeada al código es suficiente.
Podéis encontrarlo en la siguiente URL: https://github.com/capascualm/DQuantLab
14 Me gusta
Hola! Sólo comentaros que ayer terminé de leer el libro “The man who solved the market” que aquí se menciona y es una auténtica pasada. Muy recomendado.
1 me gusta
Hola de nuevo, me he aventurado a testear la estrategia que nos mostró Arturo en su artículo: “Gracias Morgan Stanley”.
Para ello, he aprovechado un modulo que te permite analizar cómo se comporta uno o varios factores ordenados por quintiles a lo largo de un periodo de tiempo determinado y si estos factores son capaces de generar alpha, así como medir el IC (Information Coefficient). Para todos aquellos que no conozcáis el uso de este, he de decir que hasta hace una semana pertenecía a ese grupo, sirve para evaluar el peso que tiene uno o varios factores sobre el portfolio. Este puede caer entre un rango de -1.0 y 1.0. Siendo 1.0 lo que tratamos de buscar en este mundo de las finanzas cuantitativas y sabiendo que un valor de 0.1 se considera cómo muy bueno.
Para el análisis he tomado las siguientes suposiciones:
• Equiponderación de ambos factores (ROA, Gross Margin)
• Universo de acciones americano
• Periodo de holding de las acciones en cartera 198d y 252d operativos (lo que son 9m y 12m naturales)
Los resultados, con comentarios, han sido los siguientes:
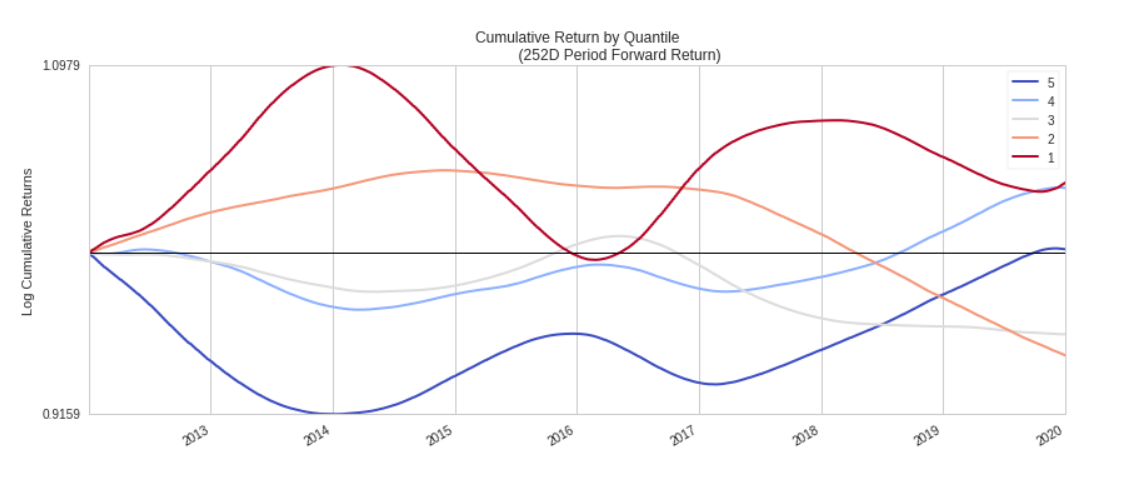
Normalmente para que uno o varios factores se consideren buenos, este gráfico debería divergir en direcciones opuestas y no “solaparse” un quintil con otro (cómo sucede), de tal forma que aquellos quintiles que son mejores tengan un resultado (logarítmico en este caso) destacado en cualquier periodo de tiempo.
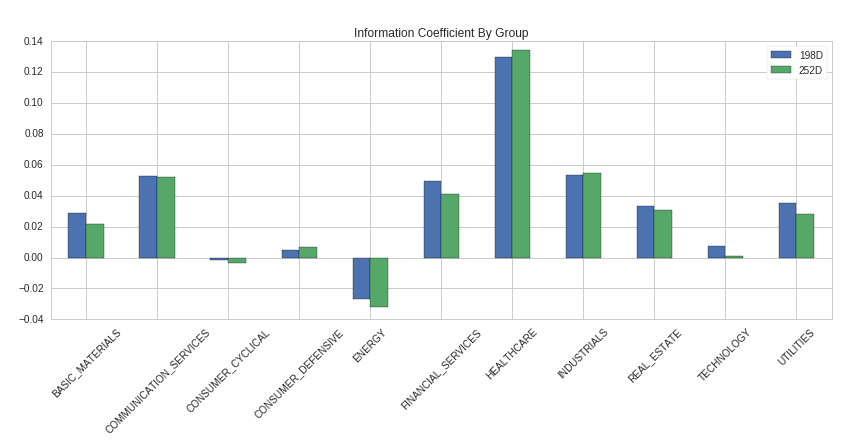
IC por sector, se ve que donde estos factores son realmente efectivos son en la industria Healthcare
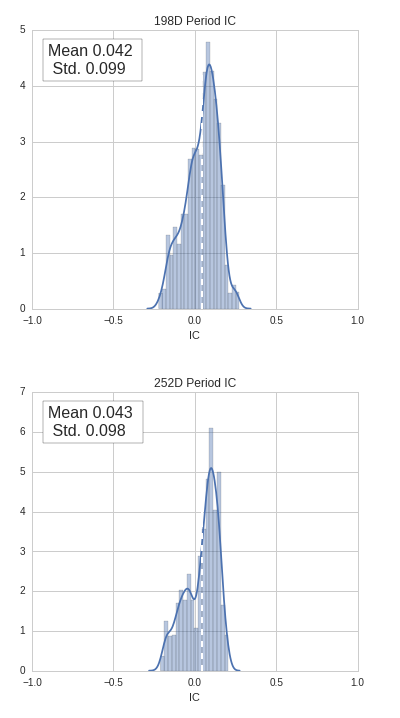
La distribución del factor IC por empresas en el periodo nos dice que parece mejor rotar los activos cada año natural, en vez de cada 9 meses.
Por último, me gustaría aprovechar para preguntaros vuestras conclusiones sobre estos resultados, ya que aunque sin ser malos no son tan buenos cómo deberían. El GM y ROA son dos factores, que, aunque no juntos, me gusta bastante utilizar, pero los números están ahí. De todos modos os animo a que reviséis el código que está en el repositorio (https://github.com/capascualm/DQuantLab/tree/master/Alphalens) y que podáis encontrar posibles ‘gaps’ que yo haya pasado por alto.
También os dejo el backtest, que este sí, supera al índice, con mucho drawdown
Un saludo 
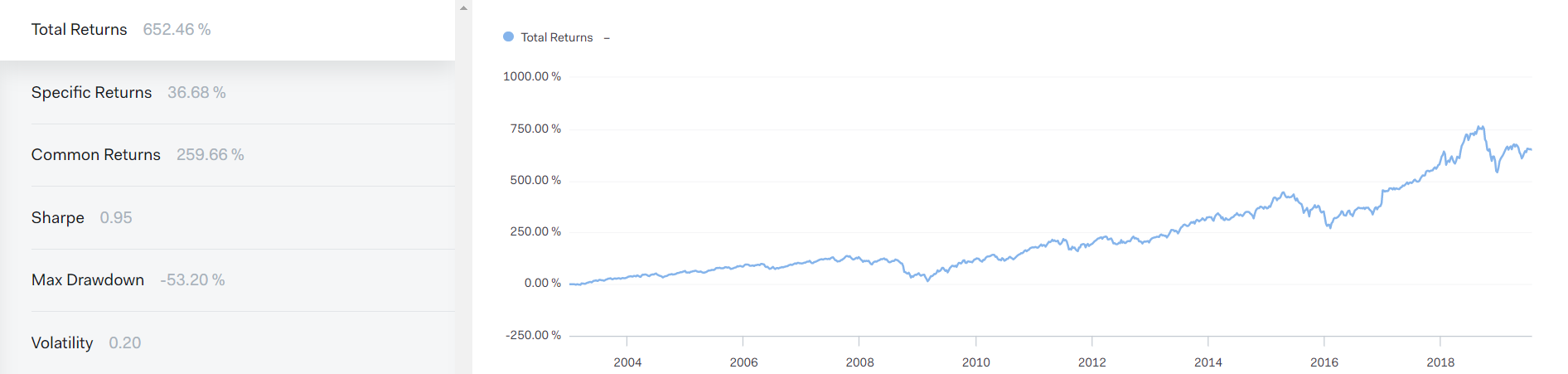
13 Me gusta
Buenas tardes. Gracias por el experimento, muy interesante (el Sharpe 0.95 no es moco de pavo). Por razones que creo que todos podrán entender, no voy a desmenuzar lo que hacemos al dedillo, pero sí le puedo adelantar, por lo que he leído (y se puede entender aunque no detallemos leyendo el artículo original), y por supuesto, con todo el respeto, el experimento que ha ejecutado tiene poco que ver con lo que hace este modelo.
Además, fíjense que si bien me interesa mucho debatir sobre criterios en sí, no voy a entrar a debatir sobre los modelos específicos que usamos en el fondo, no tanto por posibilidades de copia, que un poco sí, sino porque puede llegar un momento que algunos conceptos se puedan malinterpretar y acabar en discusiones áridas y baldías, algo así, si me permite la analogía, como fijarnos demasiado en los árboles o incluso las hojas, de forma que nos perdamos la visión del bosque.
12 Me gusta
No quiero que se malinterprete la intención del, cómo muy bien dice, experimento. Además en ningún momento he dicho que lo que se menciona en ese hilo se este replicando en el fondo. Mi única intención ha sido dar otra visión de la inversión fundamental cuantitativa, tanto desde el punto técnico, cómo desde el fundamental. Así como introducir una serie de medidas que creo que pueden resultar útiles dentro de este mundillo, que a fin de cuentas son la derivada primera de ratios fundamentales y que dan titulo al hilo.
He cogido cómo factores el Gross Margin y ROA, tremendamente conocidos en la comunidad y en la inversión cuantitativa, para ver el resultado de los mismos y que como menciono, yo mismo uso
Quiero dejar bien claro que no quiero que ningún lector pueda pensar que esto es lo que se hace en el fondo y,… pensándolo mejor quizás el fallo haya sido la mención al otro hilo.
Un saludo
7 Me gusta
A mi me ha gustado mucho su estudio, y tampoco he interpretado que hiciese referencia al fondo. (Creo lo que @arturop dice, es que el screener similar que usamos en el fondo al de Morgan Stanley, tiene criterios que si están y otros que no, pero vaya que eso también lo he entendido al leer su primer post).
Vamos, que muy agradecidos por su aportación, y le animaría a que siguiera haciendo estos análisis que son excepcionales. Compartir el curro que se ha pegado, es de una generosidad y una apertura mental digna de admirar.
Sólo me queda quitarme el sombrero, e invitarle a que siga compartiendo con nosotros los siguientes,
Buen finde @capascualm
12 Me gusta
No se preocupes. Una vez más le reitero mi admiración y el interés por aprender de Vd(s). Sólo quería aclarar posibles dudas por asociación con uno de los modelos que hemos comentado que utilizamos en el fondo, quizá un poco exageradamente, pero “nunca se sabe quién nos está leyendo”
8 Me gusta
Hola,
gracias por compartir su trabajo, se agradece! Yo me encuentro inmerso de otra serie de backtest más alejados de la zona práctica, ya que los utilizo más bien de manera educativa. Ya sé que quizás es liarse demasiado, pero si le quiere dar alguna vuelta, le recomiendo aplicar a sus backtest algún tipo de técnica de generación de datos fuera de muestra. Recordemos que la historia es una muestra de n=1. Le recomiendo que eche un vistazo a algunas técnicas de remuestreo de datos que puedan aplicarse en estos casos, en concreto a mi me parece útil el “block bootstrapping”, en el que se dividen los datos en bloques de igual longitud ( aunque hay diversas variantes y papers ) y después se generan secuencias aleatorias de estos bloques conformando nuevas mediciones .
Por otro lado, veo que ha utilizado este rango de fechas para el backtest 2012-1-1 a 2019-1-1. ¿Lo ha escogido por alguna razón en particular? Para mi escoger la fecha es un punto crucial, siempre que hago algún backtest me da dolores de cabeza.
Quizás medirlo de “pico a pico” cogiendo un ciclo completo, como comentaba @Ruben1985 le pueda interesar.
11 Me gusta
Muchas gracias por la recomendación, he estado buscando acerca de la técnica de remuestreo que comenta, pero no he sido capaz de encontrar gran cosa. Podría facilitarme dichos papers.
En relación a la fecha, si que es cierto que comienza en 2012, generalmente cuando hago esto es por lo que tarda en calcular. He de decir que previamente lo había testeado desde 2007, obteniendo resultados y conclusiones semejantes, por lo que no lo he tenido en cuenta a la hora de subir el código.
Gracias por su aportación
3 Me gusta
El problema de empezar en 2007 es que en principio aún no tenemos un ciclo completo  los value están deseándolo
los value están deseándolo 
Un libro interesante sobre los problemas del backtesting es el siguiente, uno mucho más actualizado es el de Lopez Prado que puse en el hilo:
Donde hablan de como implementar permutaciones de Montecarlo y técnicas de Bootstrapping.
He mirado en Quantopian y veo que no tienen nada similar implementado, no sé si son muy rigurosos.
Puedes echar un vistazo al módulo arch de Python donde ya tienes el trabajo bastante hecho:
https://arch.readthedocs.io/en/latest/bootstrap/bootstrap.html
Si buscas block bootstrapping quant/blog hay bastantes ejemplos por ahí, aquí tienes un notebook de jupyter por ejemplo :
Personalmente creo que el naive backtesting solo le puede llevar a uno a resultados mediocres, vamos que creo que solamente sirve para testar hipótesis y dejarlo quietecito.
Incluso entre gente supuestamente experta veo que se utilizan ciertas herramientas estadísticas de manera incorrecta.
11 Me gusta
He de decir que si el nivel es este, yo me descuelgo. No he entendido ni Flowers! 
 @AlanTuring Denos alguna pista de lo que usted habla please!
@AlanTuring Denos alguna pista de lo que usted habla please!
10 Me gusta
Yo no entiendo un pijo, pero me leo todo, por si acaso me entero por dónde sopla el aire.
16 Me gusta
Básicamente se trata de conocer los puntos débiles de un backtest.
Todos sabemos que Internet está lleno de backtest con buena pinta y que si todos funcionasen tan bien esto de la inversión no sería tan difícil y solamente bastaría con ir buscando la fórmula mágica cambiando parámetros y voilá, todo solucionado.
Las razones por las que los backtest fallan son varias, una de esas razones es que están demasiado optimizados para el periodo en el que se prueba el backtest. Para intentar comprobar lo robusto que es con datos “fuera de muestra”, se pueden generar datos que respeten unas ciertas características de los datos originales pero con información diferente.
Poniendo un ejemplo simple de una técnica de bootstrapping por bloques ( hay que hacer más conversiones pero para que se entienda ), si tenemos un fondo con esta serie temporal :
mes 1 2 3 4 5 6
precio 20 30 16 25 33 11
y queremos generar datos fuera de muestra usando un algoritmo simple, podríamos dividr estos datos en longitud de 2 meses, y las combinaciones serían [1,2], [3,4],[4,5],[6,7] … etc.
Después podríamos generar mezclas de series temporales de esos grupos haciendo permutaciones y en diferente orden, por ejemplo
[1,2]+[6,7]+[3,4]+[2,3] y esto formaría otra serie temporal además de la original, y así sucesivamente hasta generar miles de versiones del índice principal y utilizar esos datos para introducirlos al backtest.
Esto nos daría la distribución de probabilidad empírica de ese fondo con ese backtest y podríamos comprobar qué resultados nos arroja y qué tal se comporta.
Luego hay técnicas más avanzadas aplicando técnicas de inteligencia artificial, como las de máquinas de aprendizaje etc etc.
12 Me gusta