Leyendo las interesantísimas aportaciones de @agenjordi y @jvas en el hilo de Esfera III Adarve Altea (Esfera III Adarve Altea), a quienes reitero las gracias por compartir con nosotros posts que le hacen a uno reflexionar, me he decidido ha abrir este tema sobre algo a lo que hace tiempo que le doy vueltas.
Me gustaría preguntarles su opinión sobre una reflexión alrededor de la naturaleza, diferencias, semejanzas y utilidad de:
A) Backtests utilizados para diseñar una estrategia (sobreajustandola)
B) Backtests utilizados simplemente para compobar qué habría pasado, pero no usados como elemento principal a la hora de diseñar la estrategia. Según entiendo, este sería más o menos el caso de IW
C) Resultados históricos (de un fondo, estrategia, método o lo que sea)
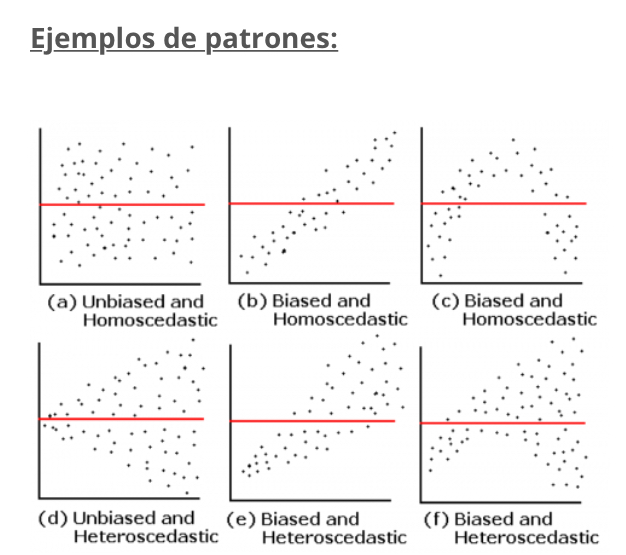
Creo que gran parte de los miembros de este foro ponen en duda la utilidad de A. Estoy de acuerdo con dicha opinión. Quienes trabajamos con modelos a diario sabemos lo fácil que es diseñar una fórmula que obtenga un resultado óptimo a toro pasado. Dicha fórmula quizás consiga, por suerte o no, captar la señal (causas fundamentales) para repetir dichos resultados en el futuro. Pero, no nos engañemos, probablemente capte más ruido que señal y nuestros resultados futuros sean decepcionantes. Últimamente me pregunto si B y C son en realidad tan distintos (o incluso si son distintos en absoluto) a A.
Empecemos con B. Evidentemente, si yo creo una fórmula (pongamos que es mi primera fórmula, pero aunque no fuese así) y al “backtestearla” (B) consigo unos “resultados” (del backtest) espectaculares, tenderé a creer que está captando señal y no ruido. Al fin y al cabo, no he creado la fórmula iterando backtests y modificando parámetros, sin tener una razón fundamental para ello. Ha sido al revés, he escrito dicha fórmula basándome en cosas que creo que tienen sentido y, al ponerla a prueba, resulta que hubiese funcionado bien en el pasado. Ya sería mucha casualidad (es decir, sería poco probable) que hubiese acertado por chiripa. Pero, ¿lo sería?
Hombre, en cierto modo sí sería poco probable. Igual que sería muy poco probable que me tocase el premio gordo de la lotería. Pero… vaya… a alguien le toca. ¿Significa esto que el método para elegir el décimo ganador captaba la señal? En principio no. Y tampoco significa que la fórmula que he creado para invertir la capte. Ojo, quizás lo hace, pero también puede ser que simplemente capte ruido, como en el caso de A.
Si solamente se crease una fórmula en el mundo, entonces sí que sería poco probable acertar a la primera. Pero hay miles o millones de personas creando fórmulas por ahí. Algunas no captan ni ruido ni señal, algunas ruido, otras señal. No digo que fijarse en backtest del tipo B no sirva absolutamente de nada. Quizás nos ayude a descartar las fórmulas que no captan ni ruido ni señal. Pero cada vez me temo más que no sirve para discernir si capta señal o solo ruido. Al fin y al cabo, si se crean millones de fórmulas (y da un poco igual que las cree un mismo equipo o miles de personas dispersas por el mundo) alguna acertará porque ha captado señal y otras por ruido. ¿No creen?
Y, EMHO, estos argumentos puesen aplicarse también a C. Corríjanme si me equivoco, pero creo que los datos históricos reales no son más que una suerte de backtest diferido. Me explico. En el momento de creación de la fórmula, ”backtest” se refiere al pasado y ”resultados reales” al futuro. Pero si cojo hoy todas las fórmulas existentes y comparo resultados históricos reales, en realidad hoy estoy haciendo una suerte de backtest. ¿No creen?
Está claro que hay diferencias. B es probablemente más costoso que A, ya que no me limito a crear una fórmula que optimice el resultado al aplicarla a ciertos datos, sino que tengo que dedicar tiempo a pensar en los fundamentos y, a partir de ellos, escribir una fórmula que creo que tiene sentido y probarla a posteriori.
C es mucho más costoso que B. No so tengo que crear una fórmula con sentido en mi opinión. Además tengo que esperar años a que haya resultados reales para aplicar lo que he denominado “backtest diferido”. Esto me lleva a intuir que quizás sea más probable que dicha fórmula capte señal que en el caso anterior. Pero ¿creen que es esta probabilidad suficiente? Supongo que dependerá de la cantidad de fórmulas que se creen en el mundo. No deja de haber un sesgo de supervivencia y, está claro, las fórmulas que capten señal tenderán a sobrevivir. Pero también lo harán durante un tiempo las que capten ruido hayan acertado por suerte.
Insisto, no digo que fijarse en B y C no sirva de nada. Al menos, hacerlo con datos de un periodo suficiente nos tendría que servir, al menos, para descartar las fórmulas que ni captan señal ni tienen suerte. ¿No creen?
@agenjordi, @jvas y @arturop, me gustaría especialmente, si son tan amables, conocer su opinión al respecto. Pero también la del resto de miembros que tengan a bien participar, está claro.
 me ha parecido siempre una locura.
me ha parecido siempre una locura.